 Jimmy Talk
Jimmy TalkGolang性能分析工具之pprof实战

通过实战来了解、熟悉 pprof 工具的使用
benchmark(基准测试) 可以度量某个函数或方法的性能,也就是说,如果我们知道性能的瓶颈点在哪里,benchmark 一是个非常好的方式。但是面对一个未知的程序,如何去分析这个程序的性能,并找到瓶颈点呢?
pprof 就是用来解决这个问题的。pprof 包含两部分:
- 编译到程序中的
runtime/pprof包 - 性能剖析工具
go tool pprof
pprof 主要可以分析 CPU、内存的使用情况、阻塞情况、Goroutine 的堆栈信息以及锁争用情况等性能问题。
该博客涉及到的项目代码:https://github.com/pjimming/go-pprof-practice
环境搭建
从 GitHub 上获取一个性能堪忧的项目,有助于更好的使用 pprof 监控到程序的性能问题。
务必确保你是在个人机器上运行“炸弹”的,能接受机器死机重启的后果(虽然这发生的概率很低)。请你务必不要在危险的边缘试探,比如在线上服务器运行这个程序。
图形化依赖安装
选择合适的包安装工具,安装图形化依赖 graphviz
| |
获取炸弹并运行
Linux(Ubuntu) 系统下:
| |
指标查看
保持程序的运行,打开浏览器访问 http://localhost:6060/debug/pprof/,可以看到如下的页面:
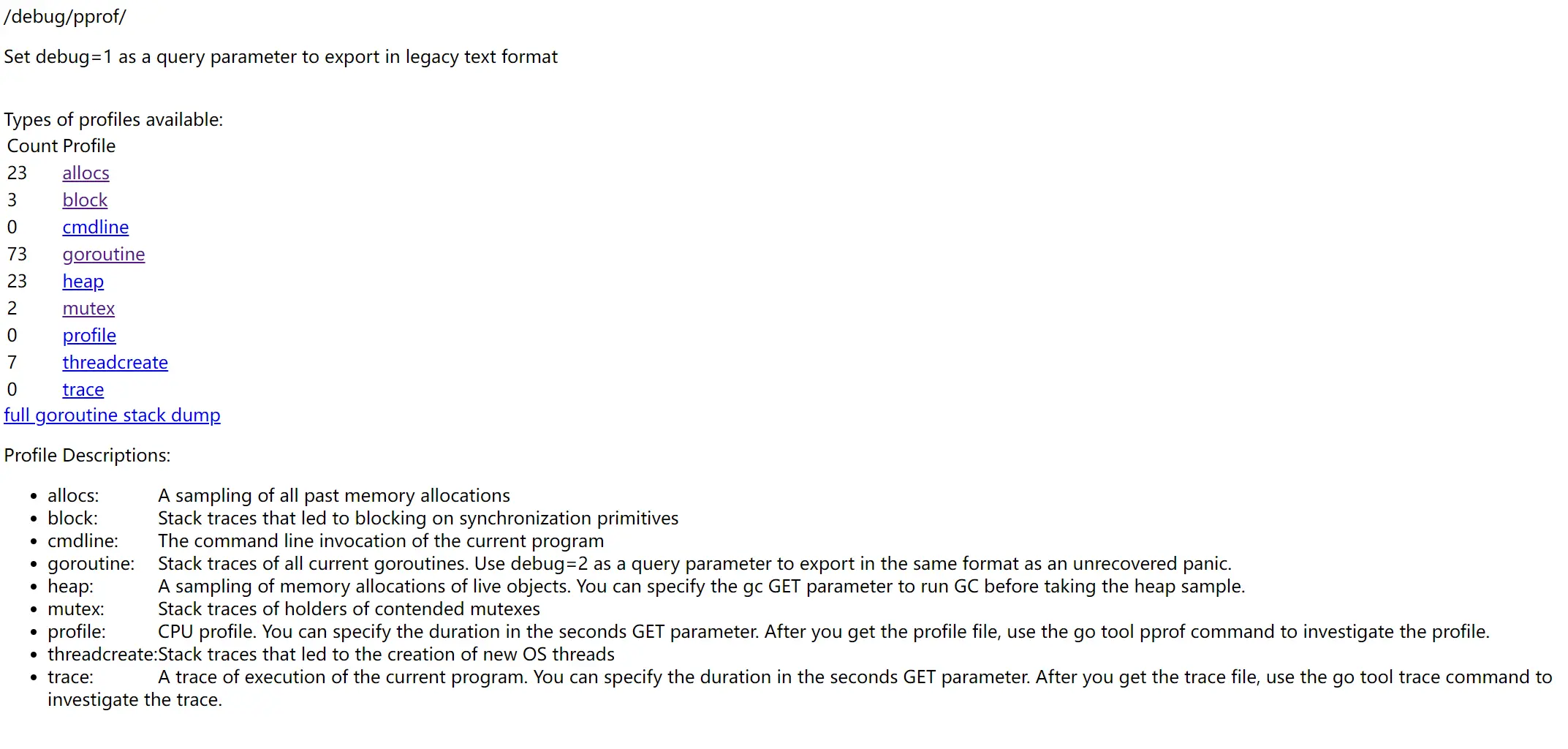
页面上展示了采样的信息,分别是:
| 类型 | 描述 |
|---|---|
| allocs | 内存分配情况的采样信息 |
| block | 阻塞操作情况的采样信息 |
| cmdline | 显示程序启动命令及参数 |
| goroutine | 当前所有协程的堆栈信息 |
| heap | 堆上内存使用情况的采样信息 |
| mutex | 锁争用情况的采样信息 |
| profile | CPU 占用情况的采样信息 |
| threadcreate | 系统线程创建情况的采样信息 |
| trace | 程序运行跟踪信息 |
由于直接阅读采样信息缺乏直观性,我们需要借助 go tool pprof 命令来排查问题,这个命令是 go 原生自带的,所以不用额外安装。
排查 CPU 占用过高
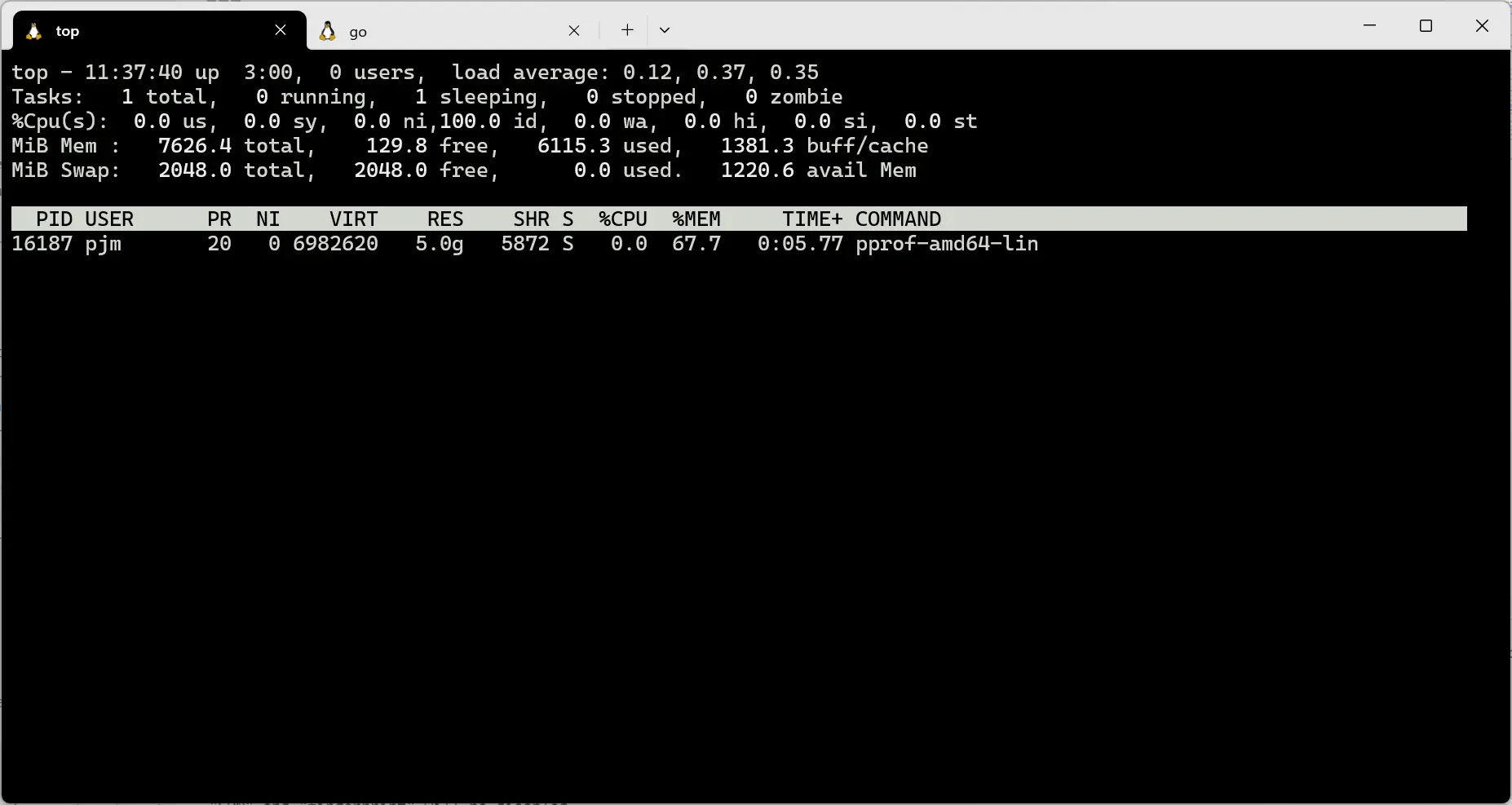
执行 top 命令,可以发现当前程序占用的 CPU 过高,如下图所示:
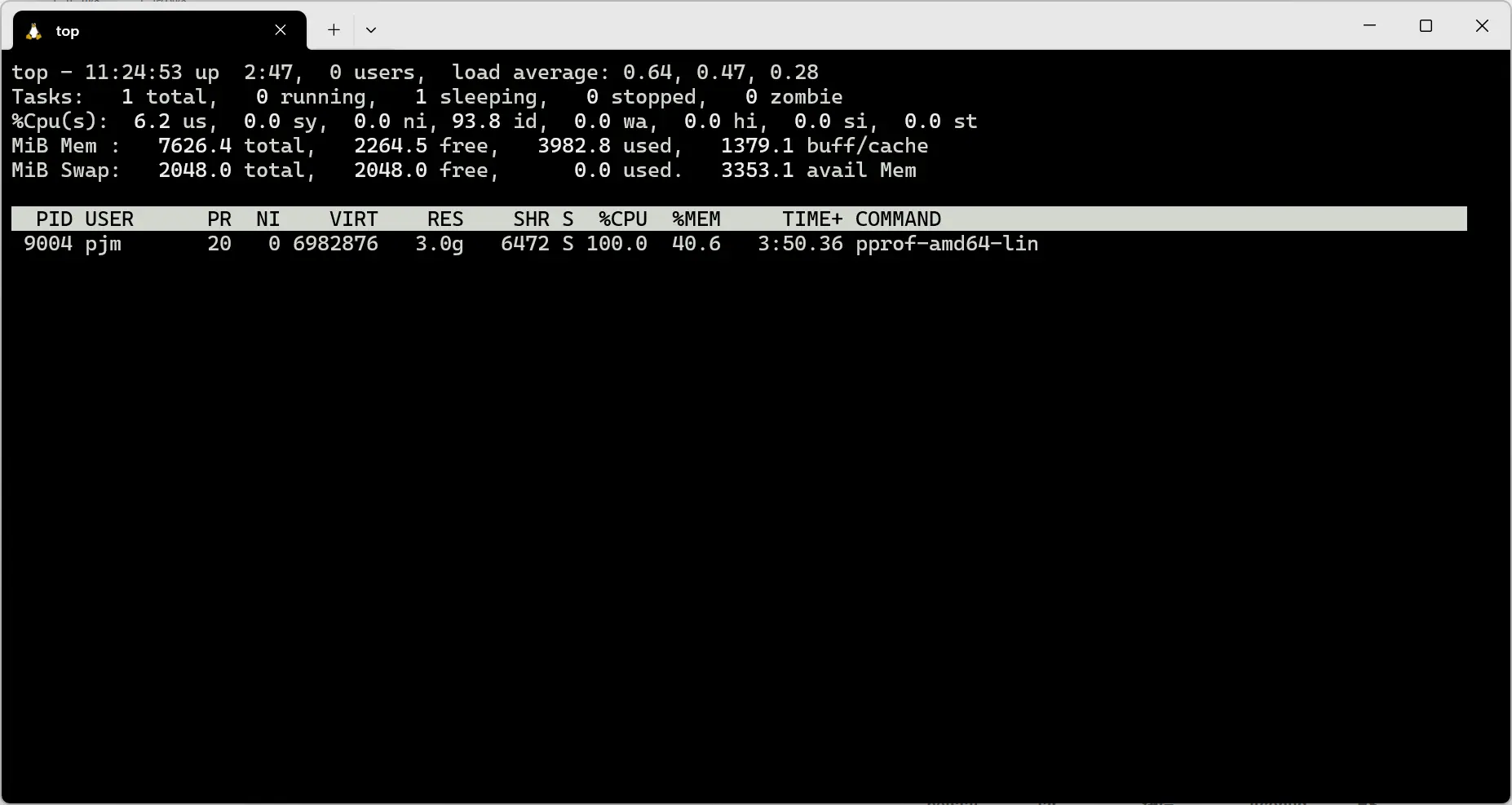
此时使用 go tool pprof 命令对 CPU 运行情况进行采样,使用下列命令,每 10s 对 CPU 使用情况进行采样。
| |
因为我们这里采集的是 profile 类型,因此需要等待一定的时间来对 CPU 做采样。你可以通过查询字符串中 seconds 参数来调节采样时间的长短(单位为秒)
等待 10s 左右之后,进入一个可交互的命令行页面:
执行 top 命令,查看 CPU 调用较高的函数:
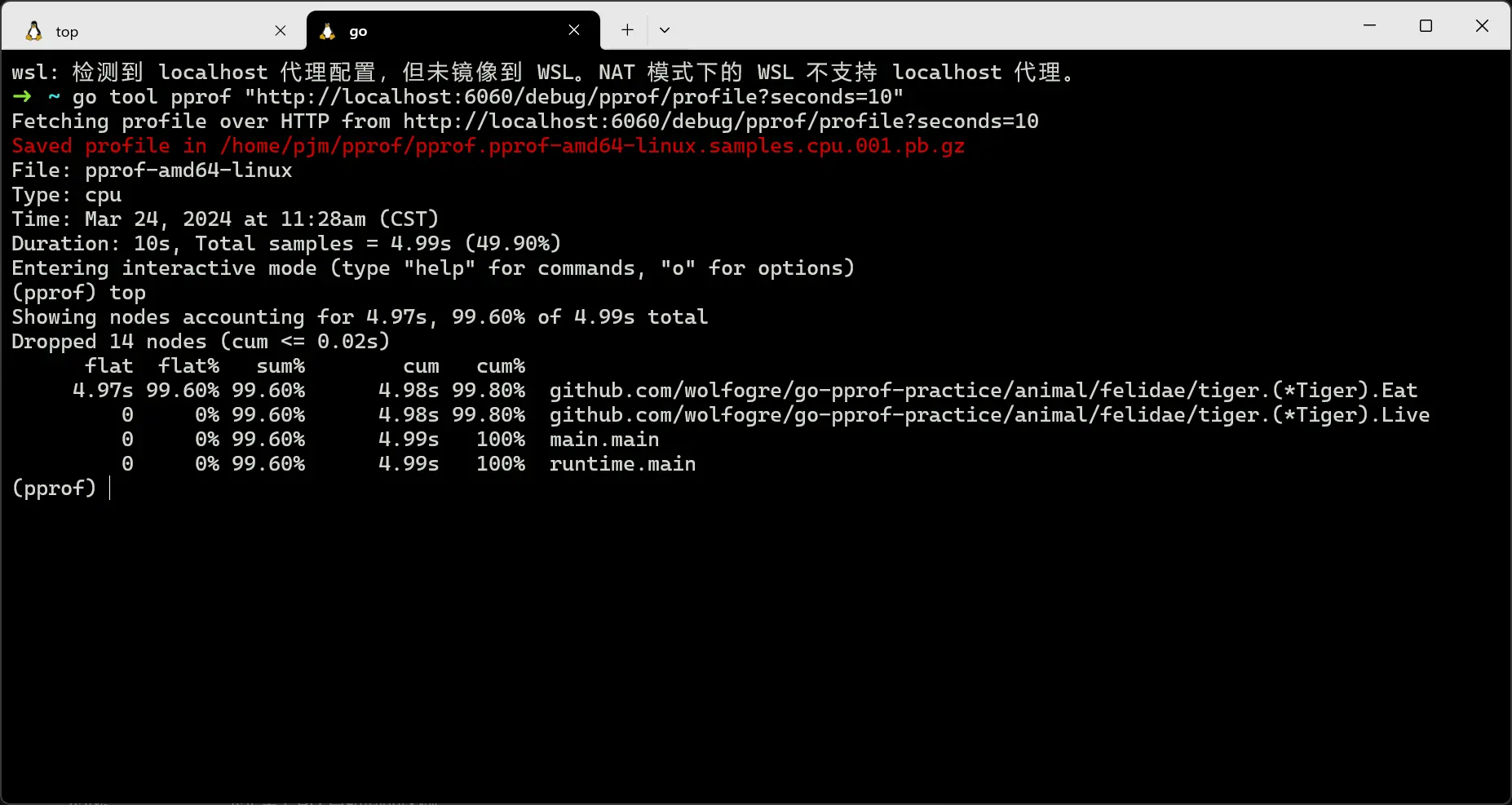
top命令
参数说明:
| 类型 | 描述 |
|---|---|
| flat | 当前函数本身的执行耗时 |
| flat% | flat 占 CPU 总时间的比例 |
| sum% | 上面每一行的 flat%总和 |
| cum | 指当前函数本身加上其调用函数的总耗时 |
| cum% | cum 占 CUP 总时间的比例 |
其中:
- $flat==cum$ 时,函数中没有调用其他函数
- $flat==0$ 时,函数中只有其他函数的调用
发现是 Eat 函数调用 CPU 过高,此时执行 list Eat 命令,查看问题具体在代码的哪一个位置:
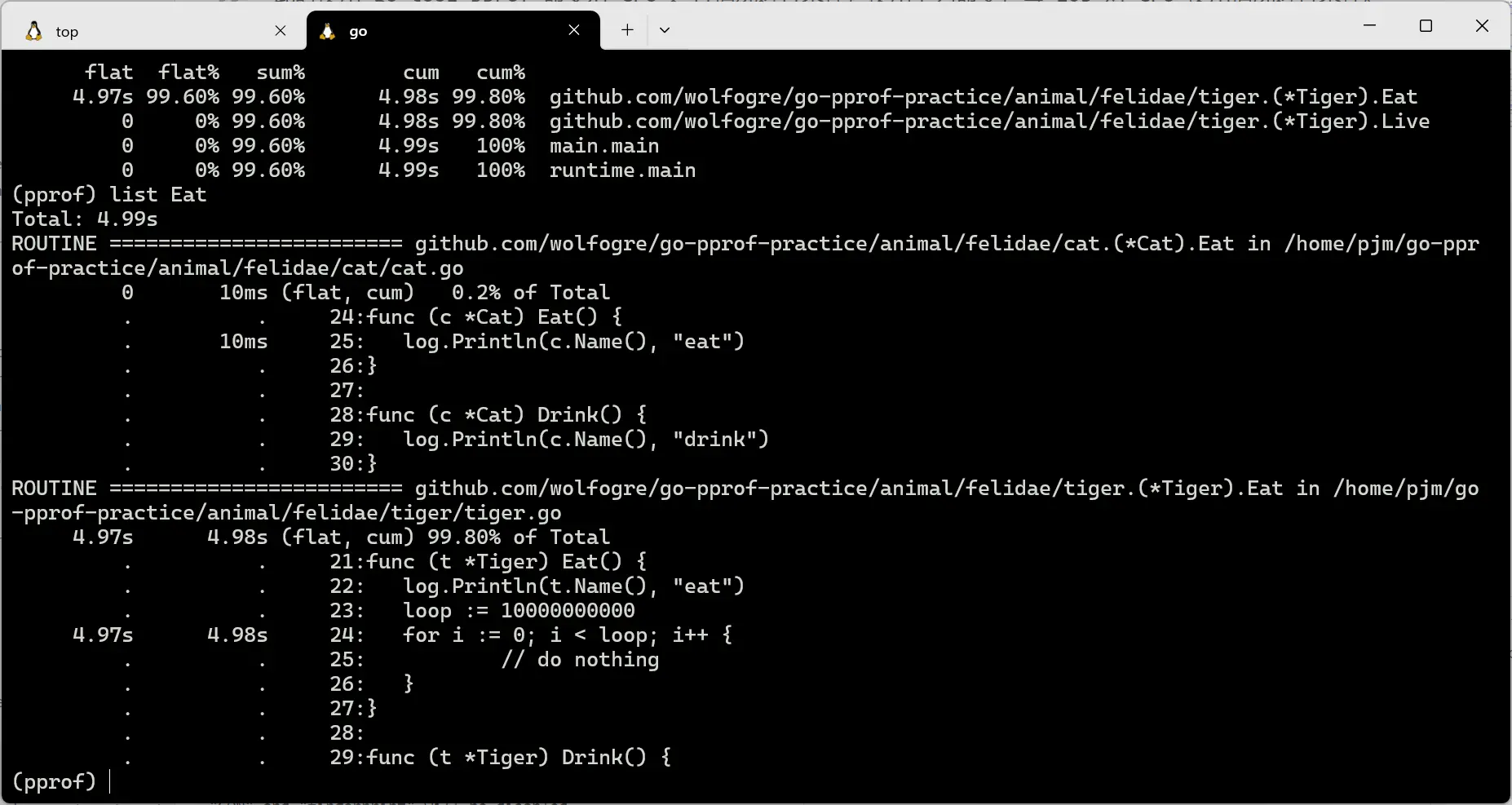
list Eat命令
从输出结果里可以看到对应的文件为 /animal/felidae/tiger/tiger.go,而且具体的代码行为 24 行的一百亿次 for 循环导致的。
我们尝试注释这段代码,并且重新编译运行,看看 CPU 使用率是否会下降
| |
中断之前的程序,重新执行 make run 命令,可以发现 CPU 的占用情况下降了。
排查内存占用过高
根据上图执行的 top 命令来看,发现程序当前占用的内存较高,我们可以通过 pprof 的 heap 来查看堆内存使用情况
执行命令:
| |
然后执行 top 命令,发现 Steal 占用大量的内存情况:
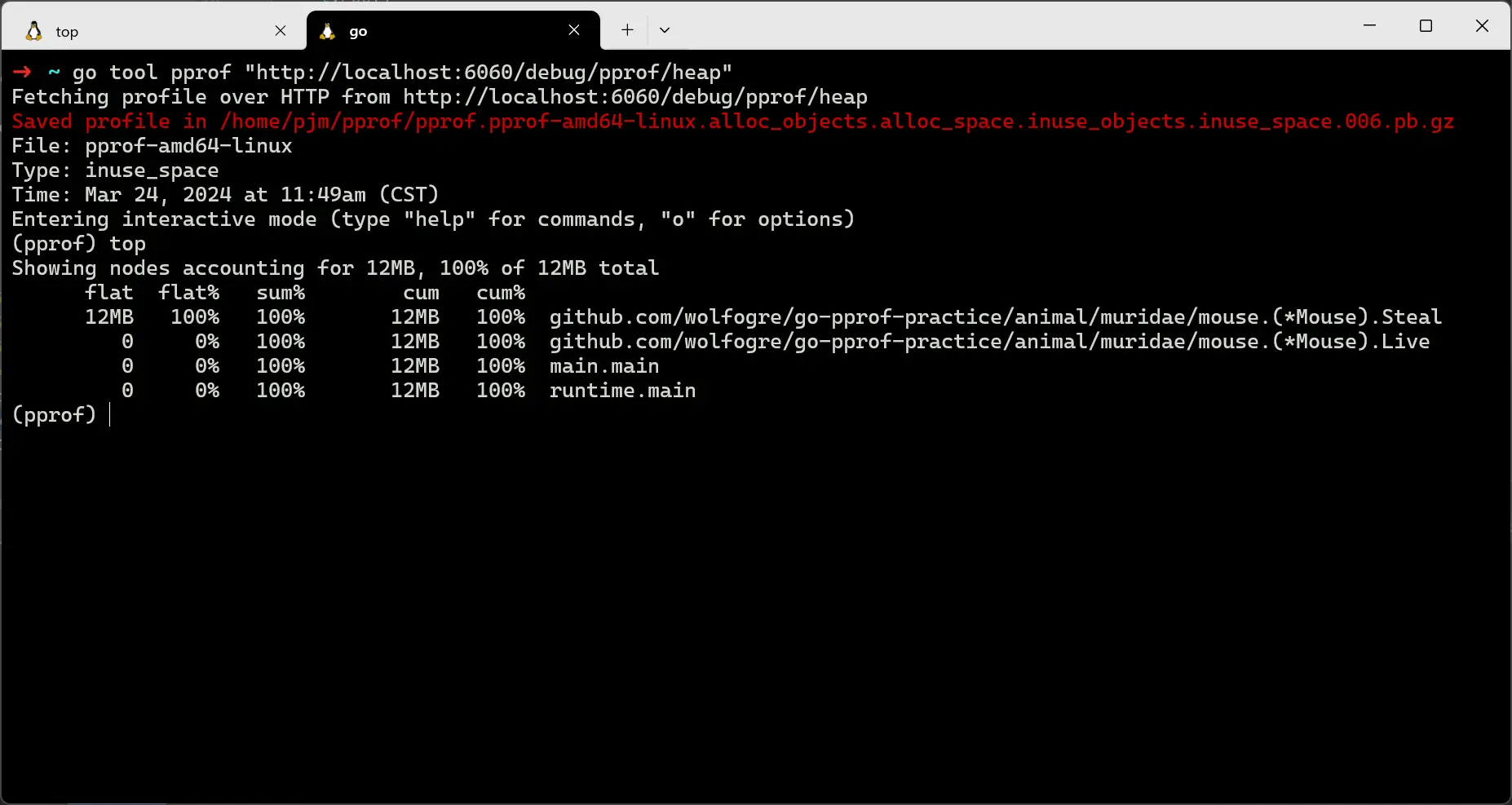
top命令
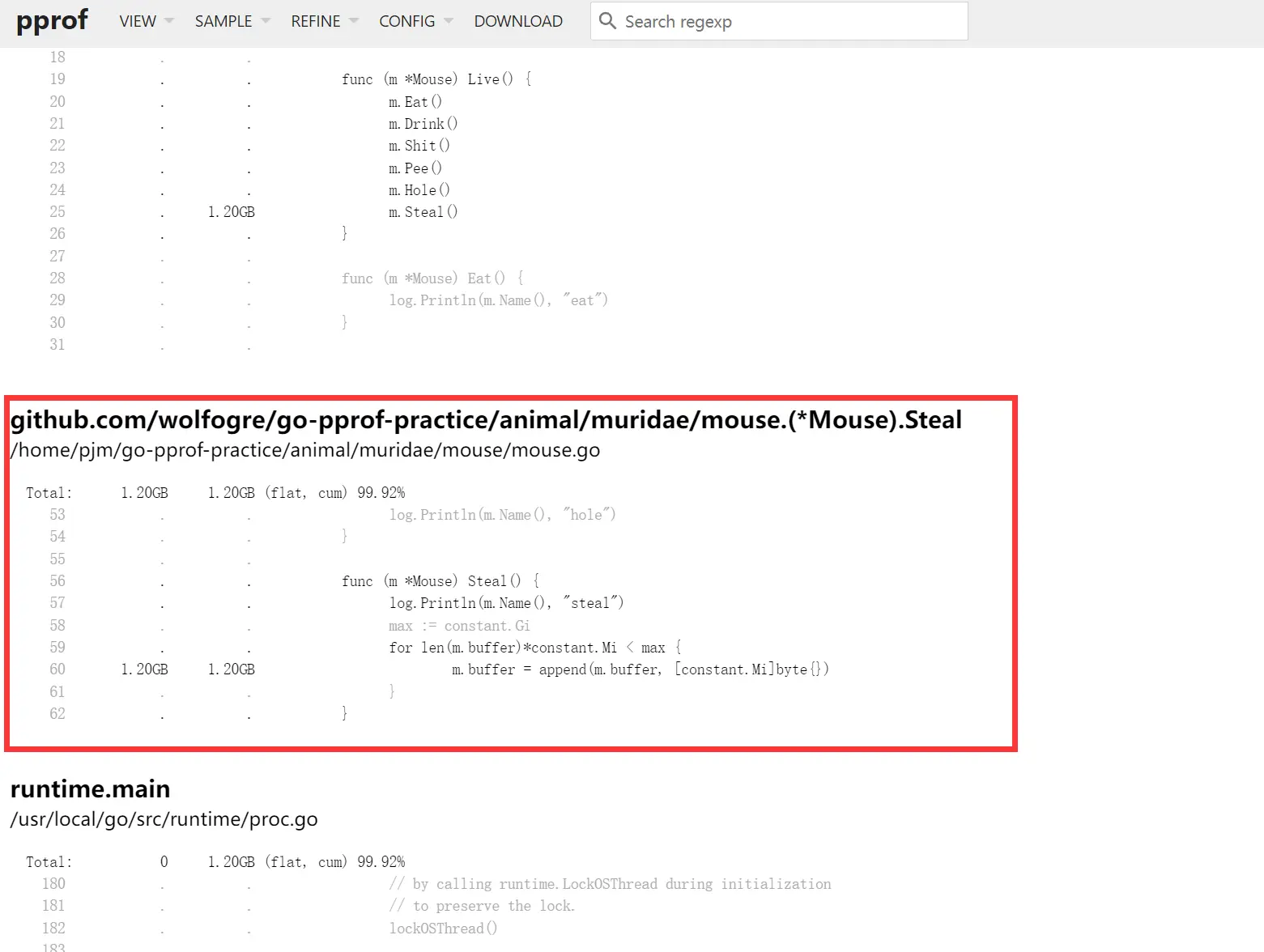
执行 list Steal 命令,查看代码细节:
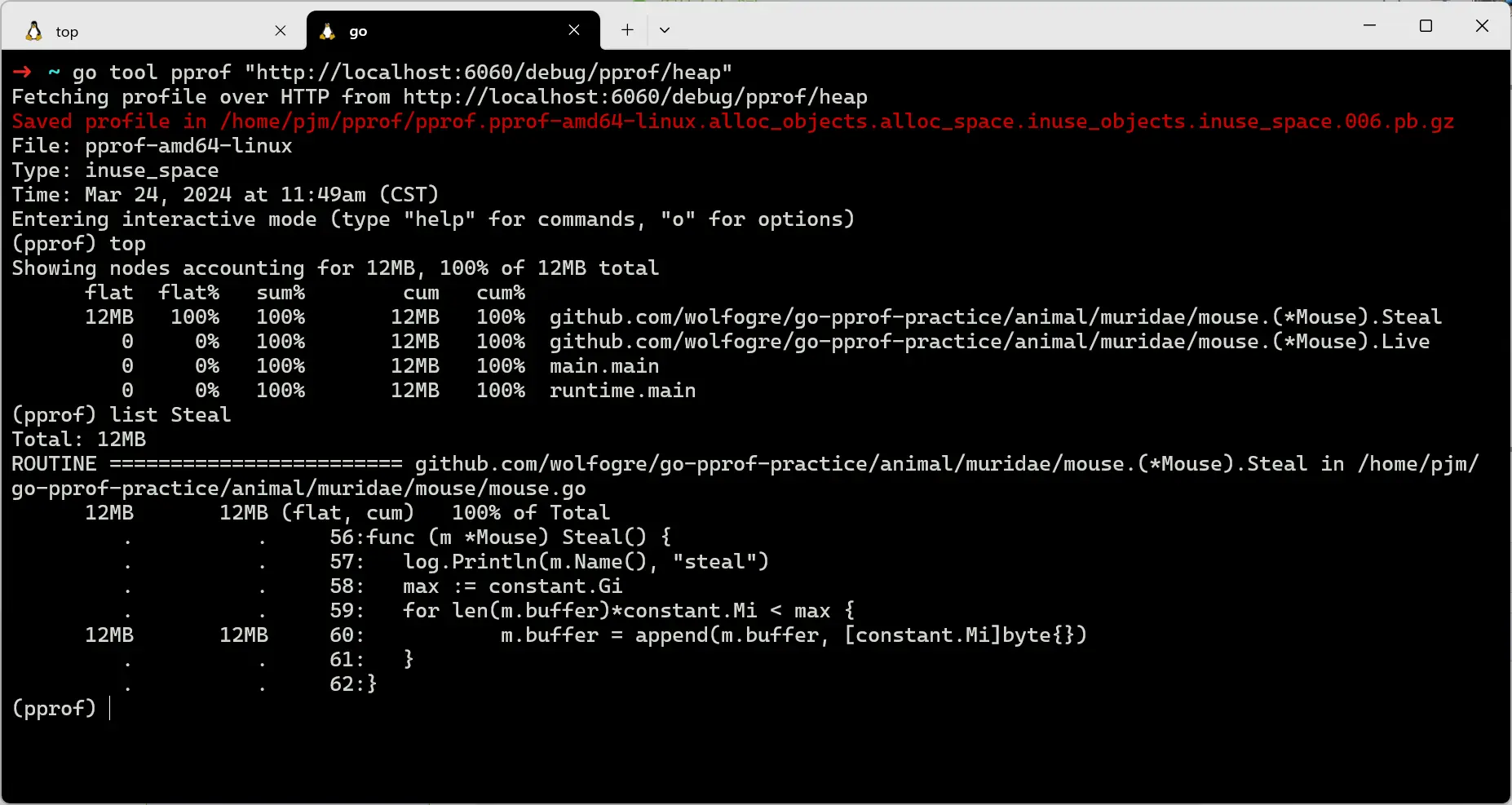
list Steal命令
根据代码细节的问题,去按照实际情况解决即可。不过我们是否还记得之前安装的图形化依赖,可以通过图形化的方式去查看性能问题。因为 web 页面可视化的方式排查比较直观,因此命令行排查的方式就不再展开了,输入以下命令可以看到堆内存的占用情况:
| |
这个命令中 http 选项将会启动一个 web 服务器并自动打开网页。其值为 web 服务器的 endpoint
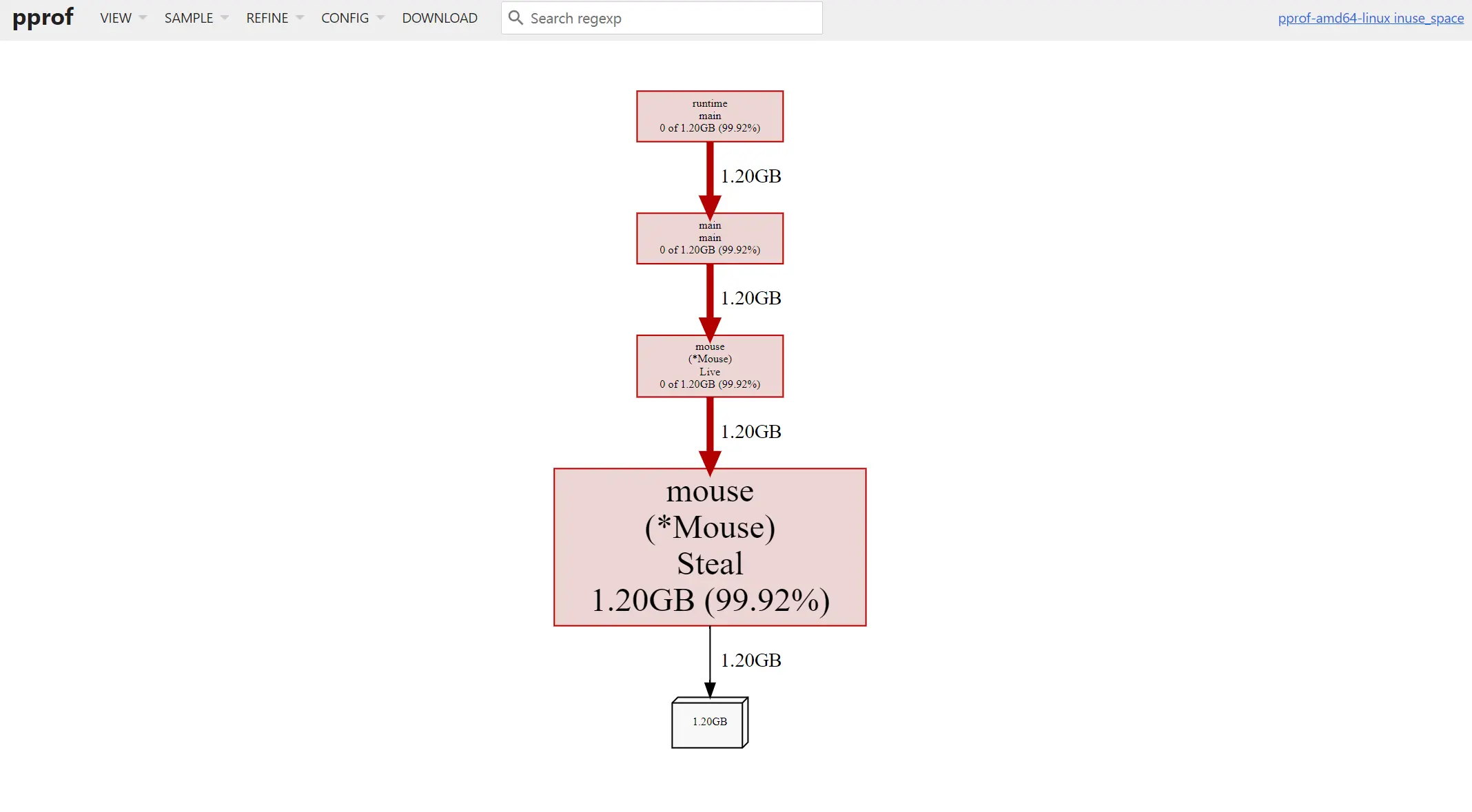
从上图我们可以发现 Mouse 类的 Steal 方法占用了大量的内存。我们点击 VIEW -> Source 可以看到具体代码文件、行数以及资源使用情况。
注释掉相关代码,重新编译运行,再次查看资源消耗的情况,可以发现 CPU 和内存都占用较低了。
其中在 web 页面上,SIMPLE 里有四个选项,他们的含义为:
| 类型 | 描述 |
|---|---|
| alloc_objects | 程序累计申请的对象数 |
| alloc_space | 程序累计申请的内存大小 |
| inuse_objects | 程序当前持有的对象数 |
| inuse_space | 程序当前占用的内存大小 |
在堆内存采样中,默认展示的是 inuse_space 视图,只展示当前持有的内存,但如果有内存已经释放,这是 inuse 采样就不会展示了。
在后续排查 GC 问题的时候,也可以根据 alloc_space 指标来排查。
排查频繁内存回收
你应该知道,频繁的 GC 对 golang 程序性能的影响也是非常严重的。虽然现在这个炸弹程序内存使用量并不高,但这会不会是频繁 GC 之后的假象呢?
为了获取程序运行过程中 GC 日志,我们需要先退出炸弹程序,再在重新启动前赋予一个环境变量,同时为了避免其他日志的干扰,使用 grep 筛选出 GC 日志查看:
| |
可以发现打出的 log 信息,分析可以发现,GC 差不多每 3 秒就发生一次,且每次 GC 都会从 16MB 清理到几乎 0MB,说明程序在不断的申请内存再释放,这是高性能 golang 程序所不允许的。
| |
此外也可以通过 heap 的 alloc_space 视图来查看。执行命令:
| |
选择 SIMPLE->alloc_space,发现 Dog 方法申请了大量的内存。
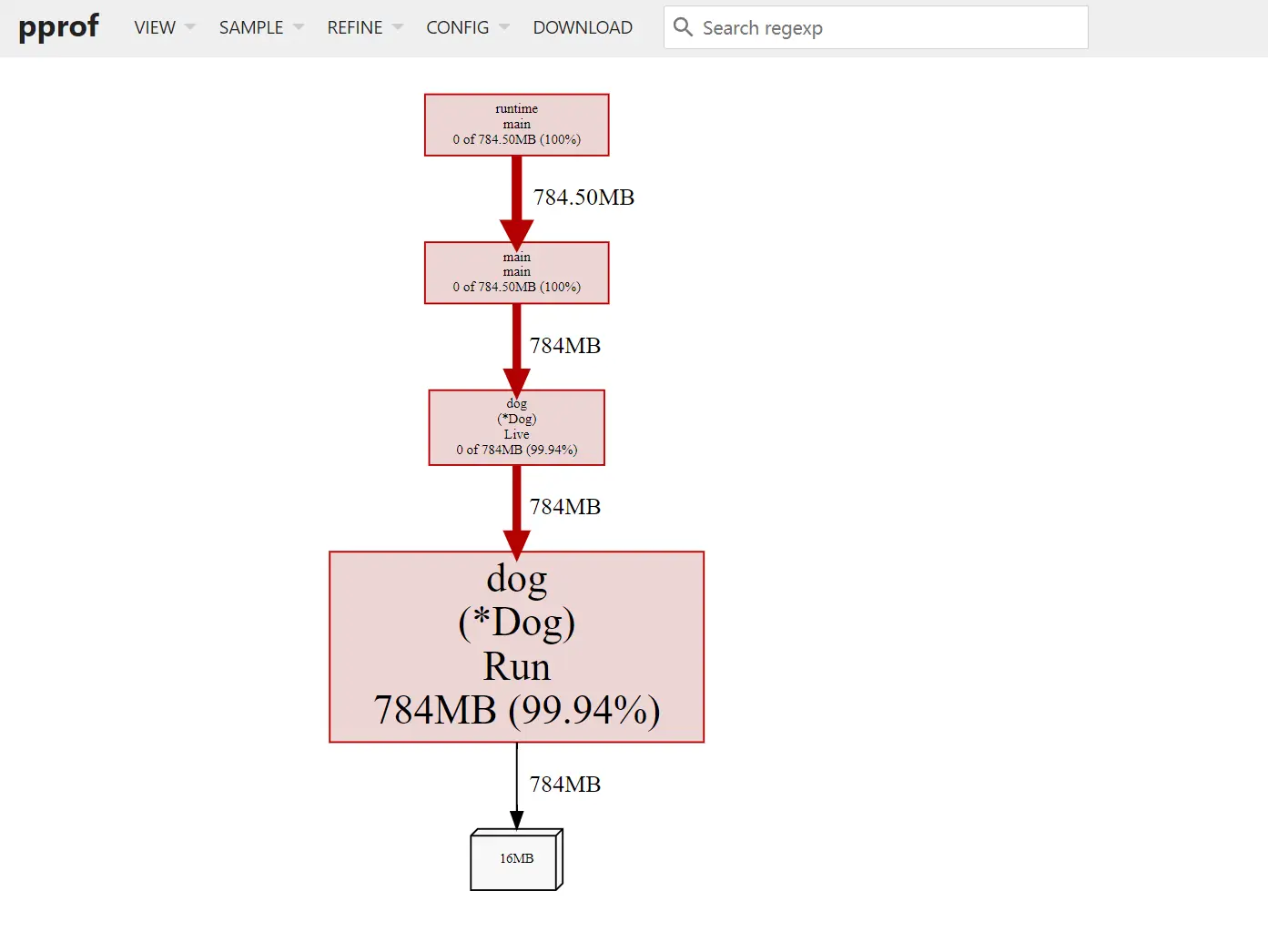
查看源码分析代码的问题,原来是 Run 方法在不断的申请内存。
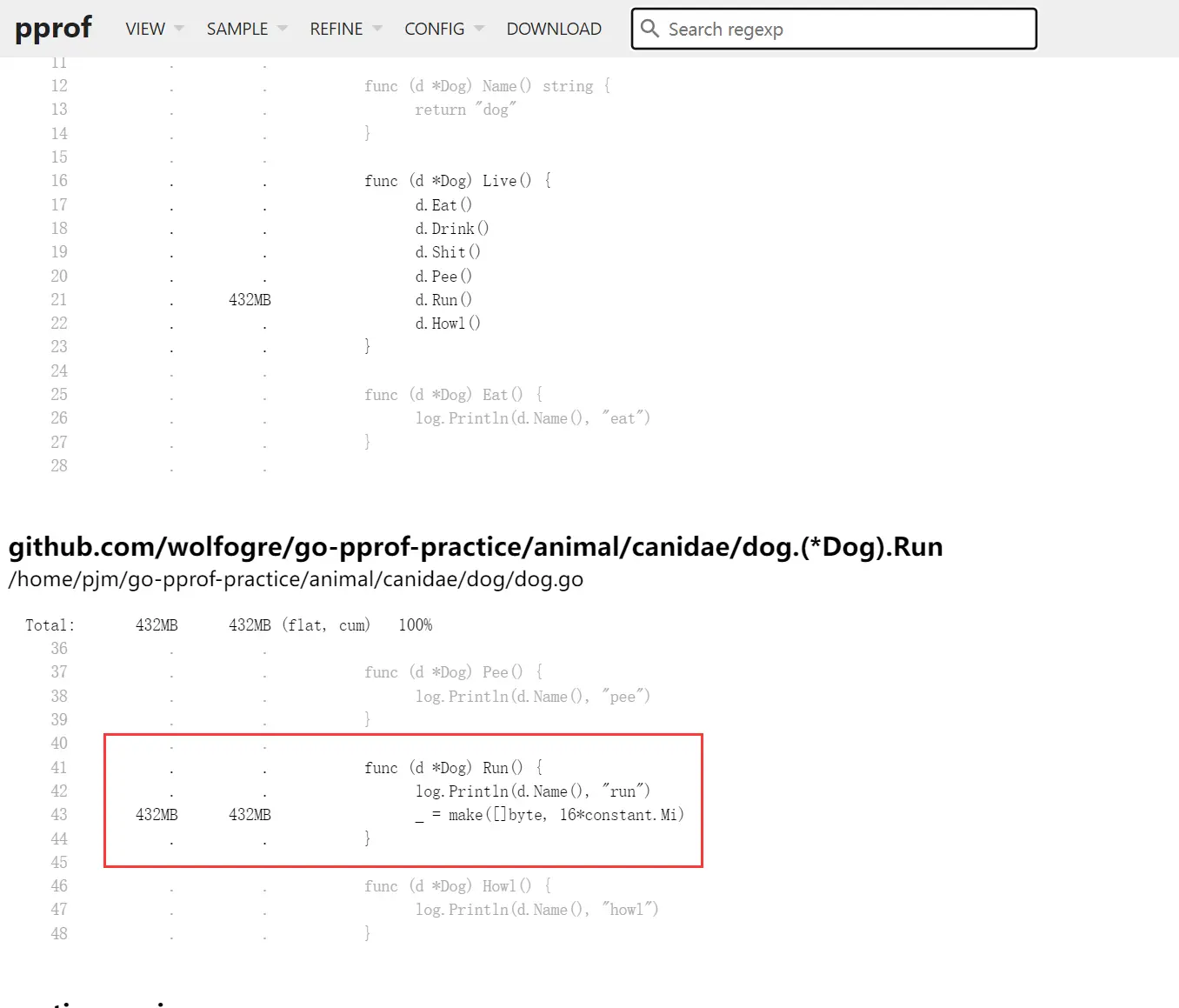
这里有个小插曲,你可尝试一下将 16 * constant.Mi 修改成一个较小的值,重新编译运行,会发现并不会引起频繁 GC,原因是在 golang 里,对象是使用堆内存还是栈内存,由编译器进行逃逸分析并决定,如果对象不会逃逸,便可在使用栈内存,但总有意外,就是对象的尺寸过大时,便不得不使用堆内存。所以这里设置申请 16 MiB 的内存就是为了避免编译器直接在栈上分配,如果那样得话就不会涉及到 GC 了。
我们同样注释掉问题代码,重新编译执行,可以看到这一次,程序的 GC 频度要低很多,以至于短时间内都看不到 GC 日志了:
排查协程泄漏问题
在http://localhost:6060/debug/pprof/页面可以发现,协程的数量居然多达 100 多个,这对这个小程序来说,是不正常的,通过运行下列命令,去查看到底是怎么回事
| |
得到图形化页面,如下图所示:

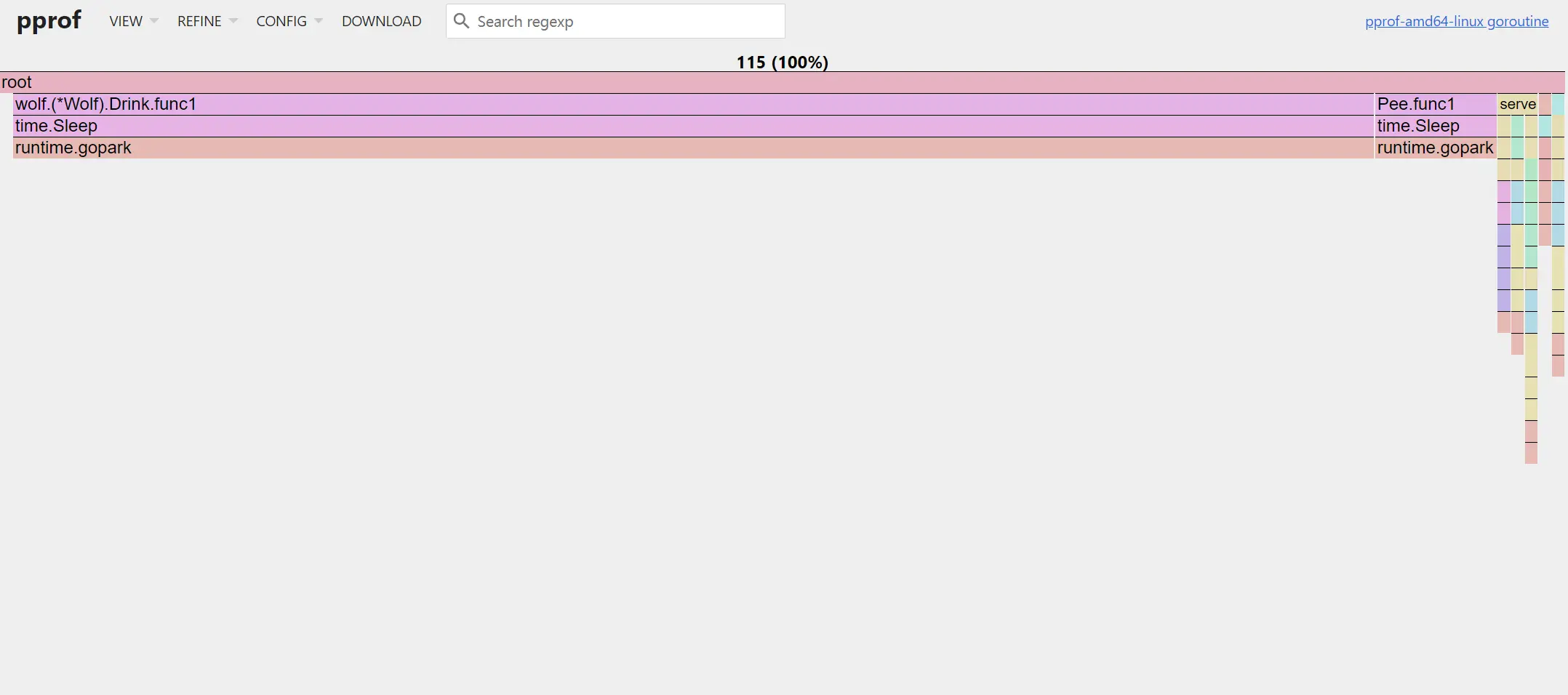
发现调用的链路比较长,此时我们可以通过火焰图来更直观的查看,点击 VIEW->Flame Graph,我们可以发现是 Wolf.Drink() 这个函数产生了大量的协程。
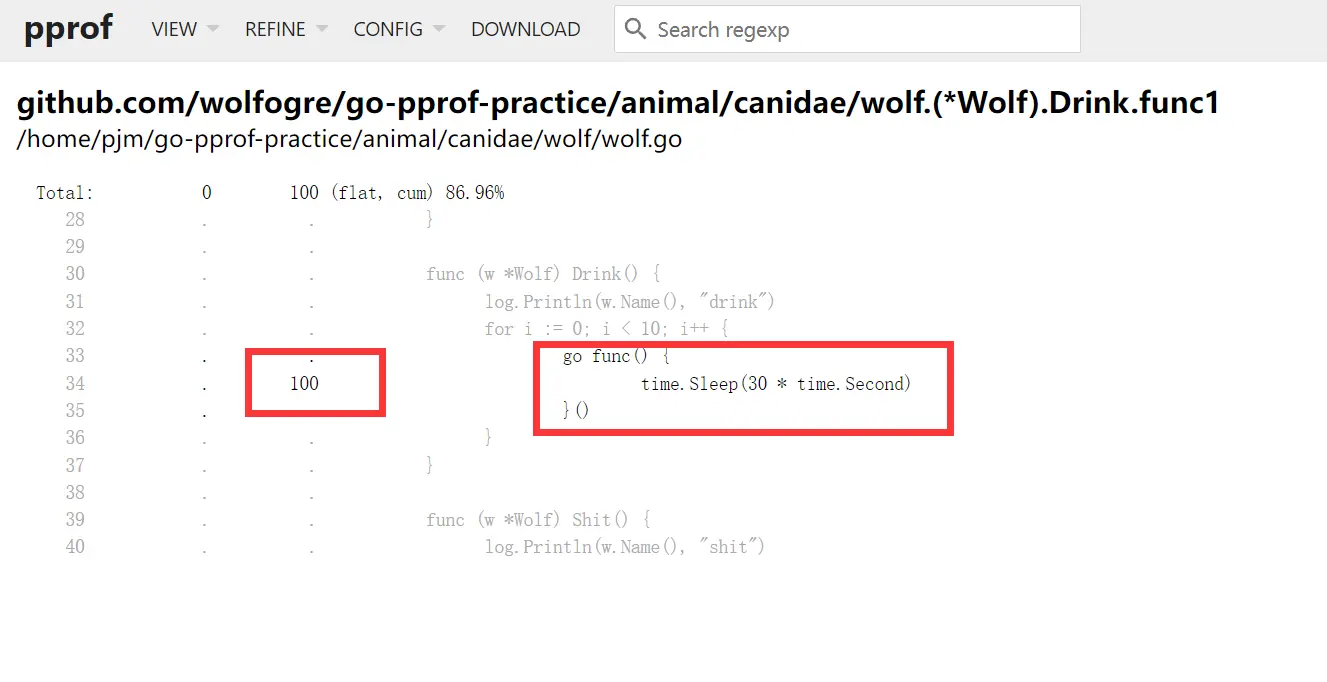
在 VIEW->Source 里,输入 Drink 来查询代码细节,可以看到,Drink 方法每次会起 10 个协程,每个协程会 sleep 30 秒再推出,而 Drink 函数又被反复的调用,这才导致了大量的协程泄漏。
试想一下,如果我们业务中起的协程会永久阻塞,那么泄漏的协程数量便会持续增加,从而导致内存的持续增加,那么迟早会被 OS Kill 掉。我们通过注释掉问题代码,重新运行可以看到协程数量已经降低到个位数的水平了。
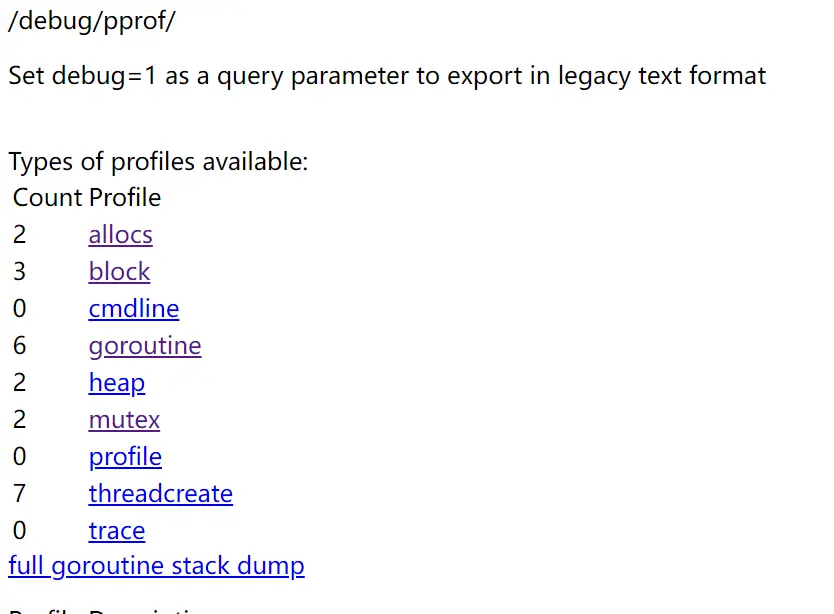
排查锁的争用关系
到目前为止,我们已经基本解决了这个炸弹程序所有的资源占用问题,但是日常业务中不仅仅有资源占用问题,还有性能问题。
下面将开始对性能进行优化,首先能想到的就是不合理的锁竞争,比如加锁时间过长。发现 debug 页面里存在锁的竞争情况。执行下列命令进行查看。
| |
可以发现 Wolf 这个类里,存在锁长时间等待问题。
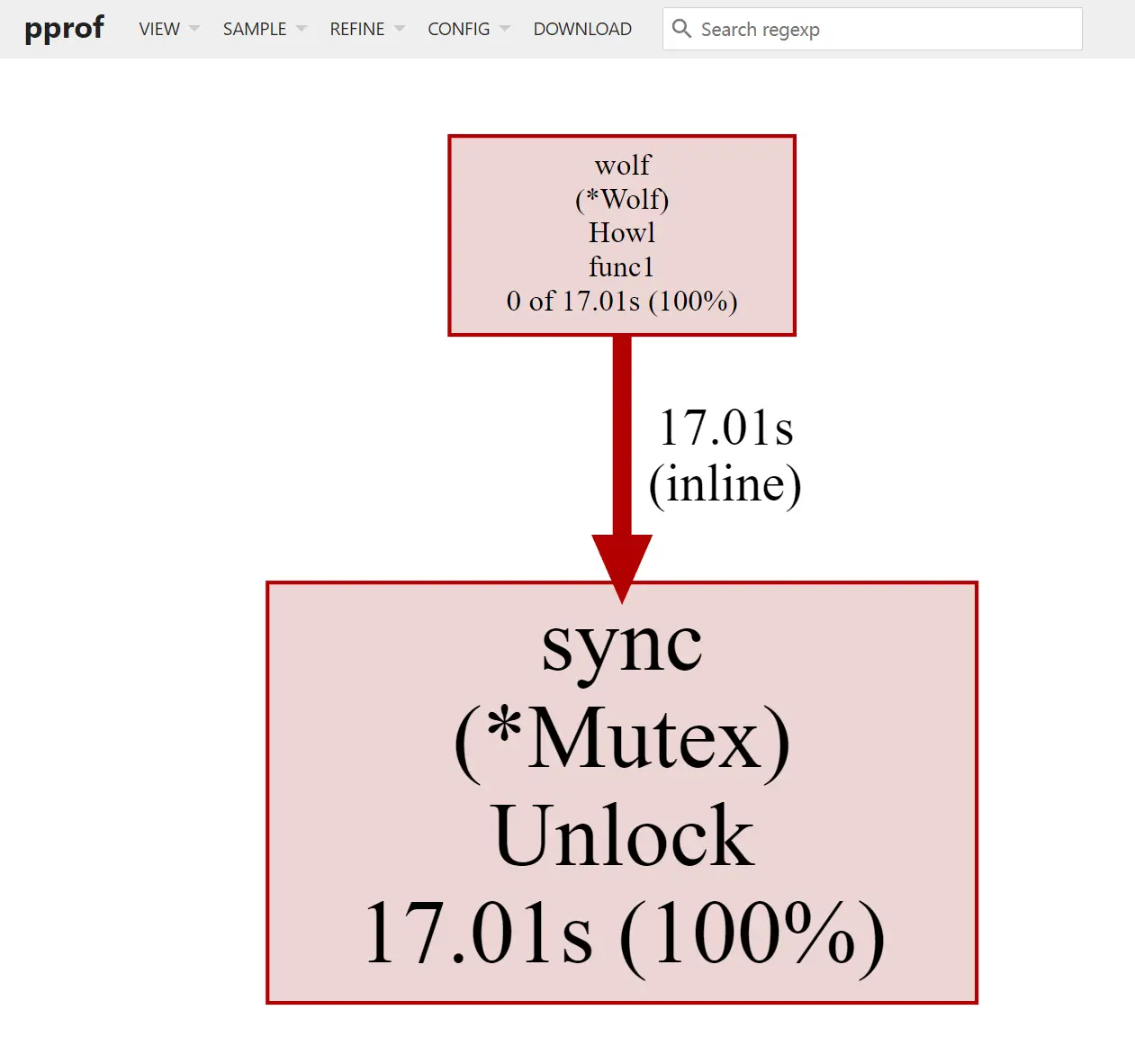
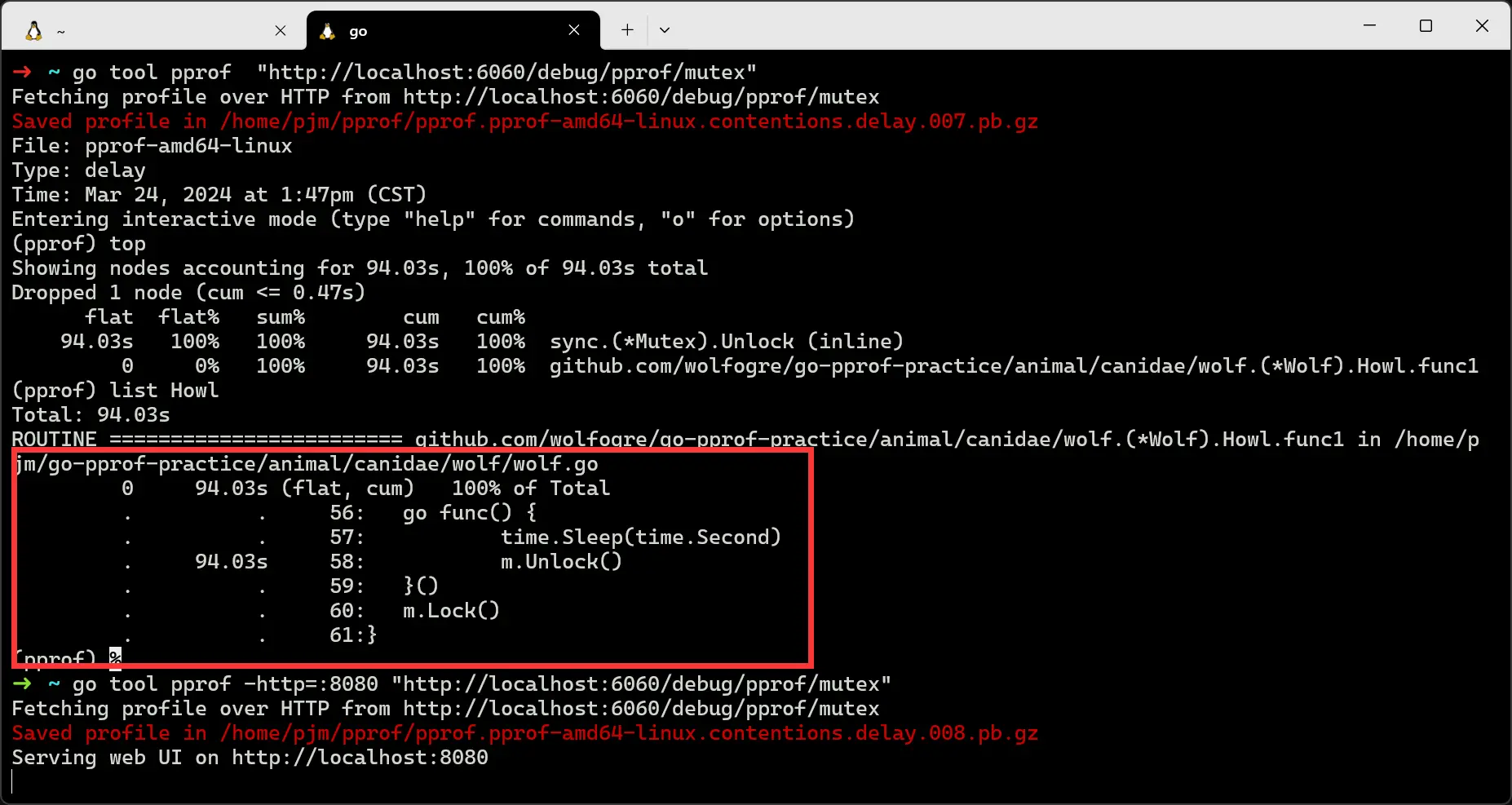
可以看到,这个锁由主协程 Lock,并启动子协程去 Unlock,主协程会阻塞在第二次 Lock 这里等待子协程完成任务,但由于子协程足足睡眠了一秒,导致主协程等待这个锁释放足足等了一秒钟。我们对此处代码进行修改即可修复问题。
排查协程阻塞问题
除了锁会阻塞之外,还有很多逻辑会导致当前协程阻塞。可以发现 debug 页面上,存在两个 block。
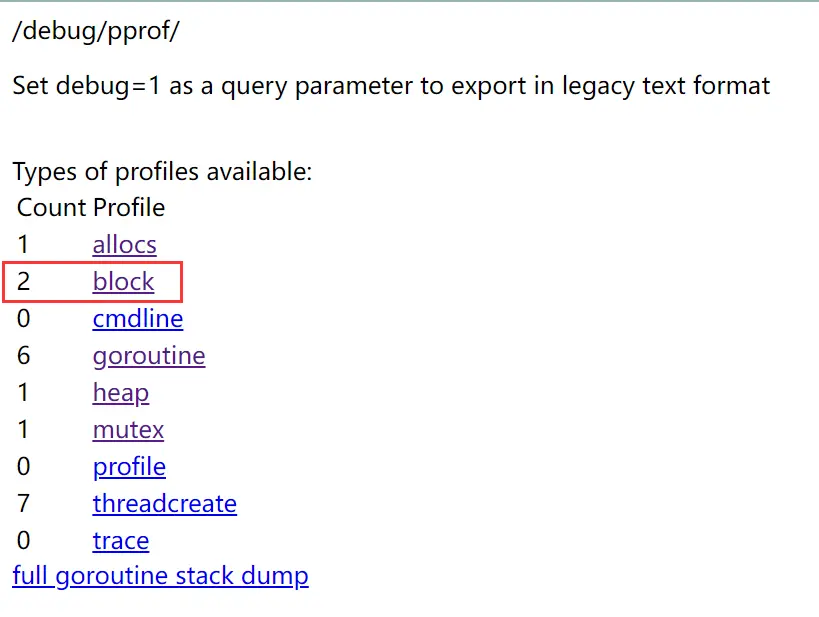
执行命令查看 block 信息:
| |
可以发现存在 Cat 类的方法导致存在协程阻塞。
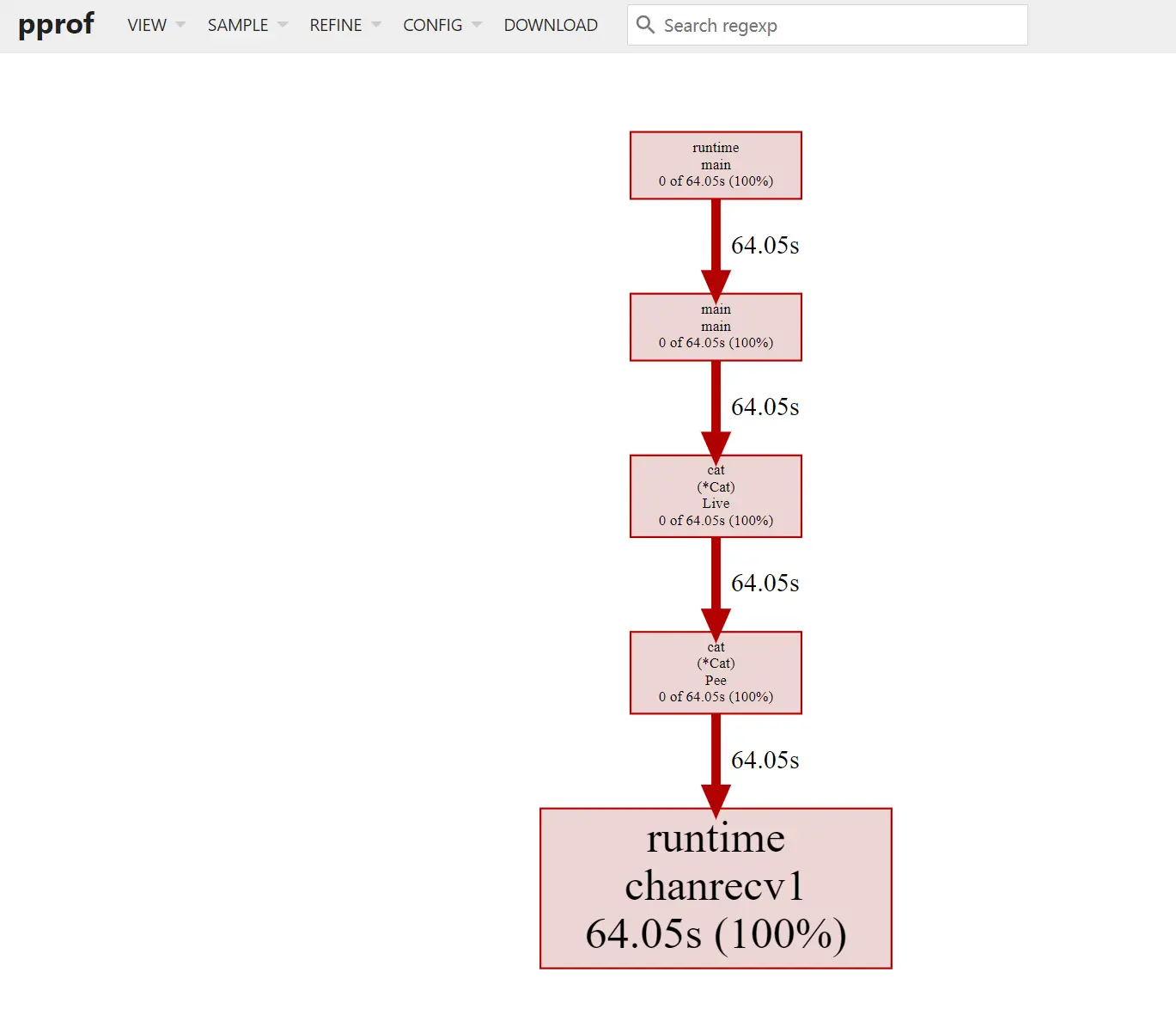
查询 Cat 涉及到的源码
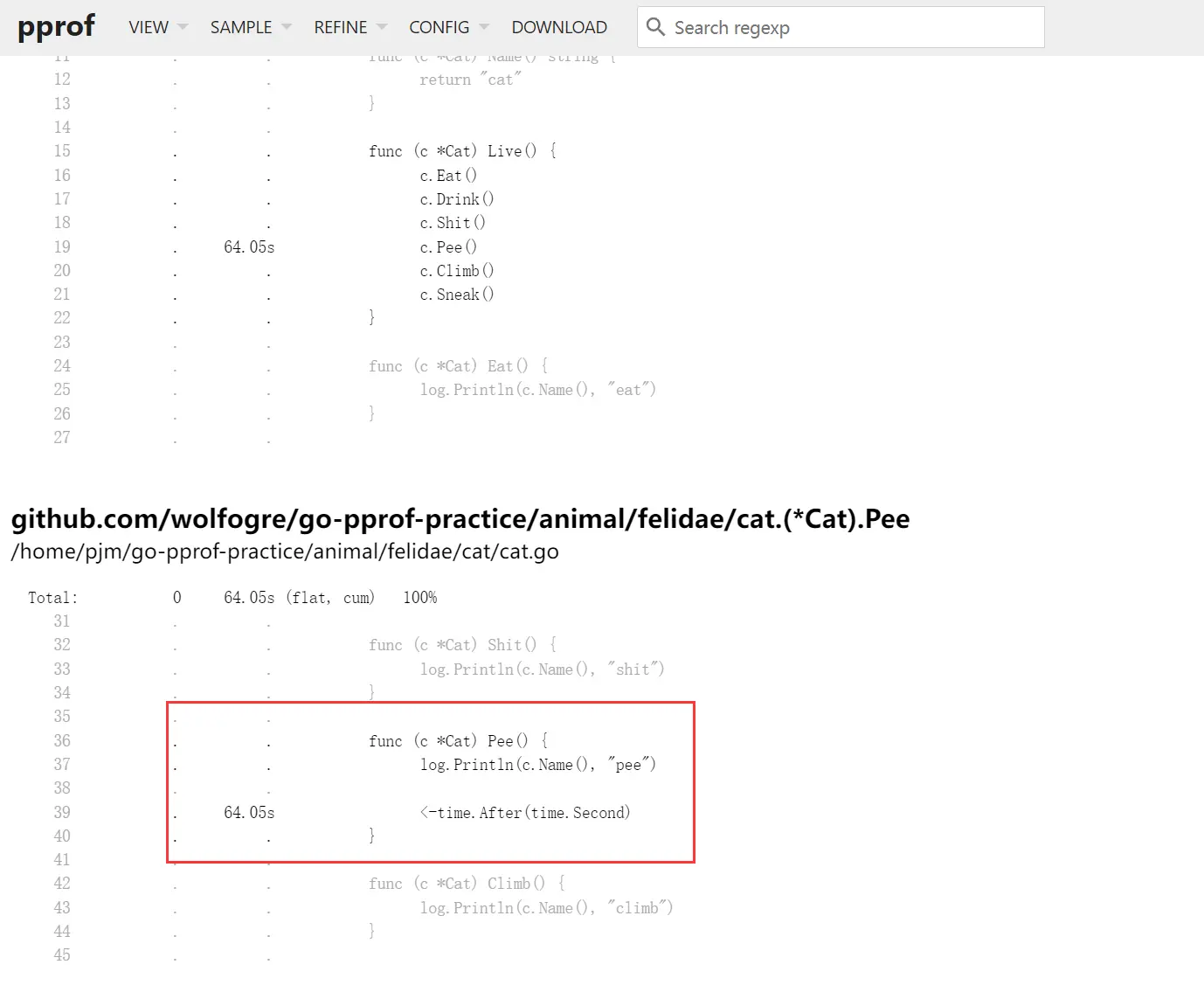
可以看到这里不同于直接 sleep 一秒,这里是从一个 channel 里读数据时,发生了阻塞。直到这个 channel 在一秒后才有数据读出,因此这里会导致程序阻塞,而不是睡眠。
我们对此代码注释掉,重新编译运行后发现程序还有一个 block。通过排查分析后我们发现是因为程序提供了 HTTP 的 pprof 服务,程序阻塞在对 HTTP 端口的监听上,因此这个阻塞是正常的。
排查内存泄漏
pprof 中有一个 -base 选项,它用于指定基准采样文件,这样可以通过比较两个采样数据,从而查看到指标的变化,例如函数的 CPU 使用时间或内存分配情况。
举个具体的例子,在业务中有一个低频调用的接口存在内存泄漏(OOM),它每被调用一就会泄漏 1MiB 的内存。这个接口每天被调用 10 次。假设我们给这个服务分配了 100MiB 空余的内存,也就是说这个接口基本上每十天就会挂一次,但当我们排查问题的时候,会发现内存是缓慢增长的。此时如果你仅通过 pprof 采样单个文件来观察,基本上很难会发现泄漏点。
这时候 base 选项就派上用场了,我们可以在服务启动后采集一个基准样本,过几天后再采集一次。通过比对这两个样本增量数据,我们就很容易发现出泄漏点。
同样的,这个炸弹我也已经预埋了这样一个缓慢的泄漏点,但时间我缩短了一下。相信在上面的实操过程中你也发现了端倪,下面我们开始实操一下。
我们运行这个炸弹程序,将启动时的堆内存分配情况保存下来,你可以在 debug 页面点击下载,也可以在终端中执行 curl -o heap-base http://localhost:6060/debug/pprof/heap 来下载。
在资源管理器中我们可以看到程序刚启动的时候,内存占用并不高:
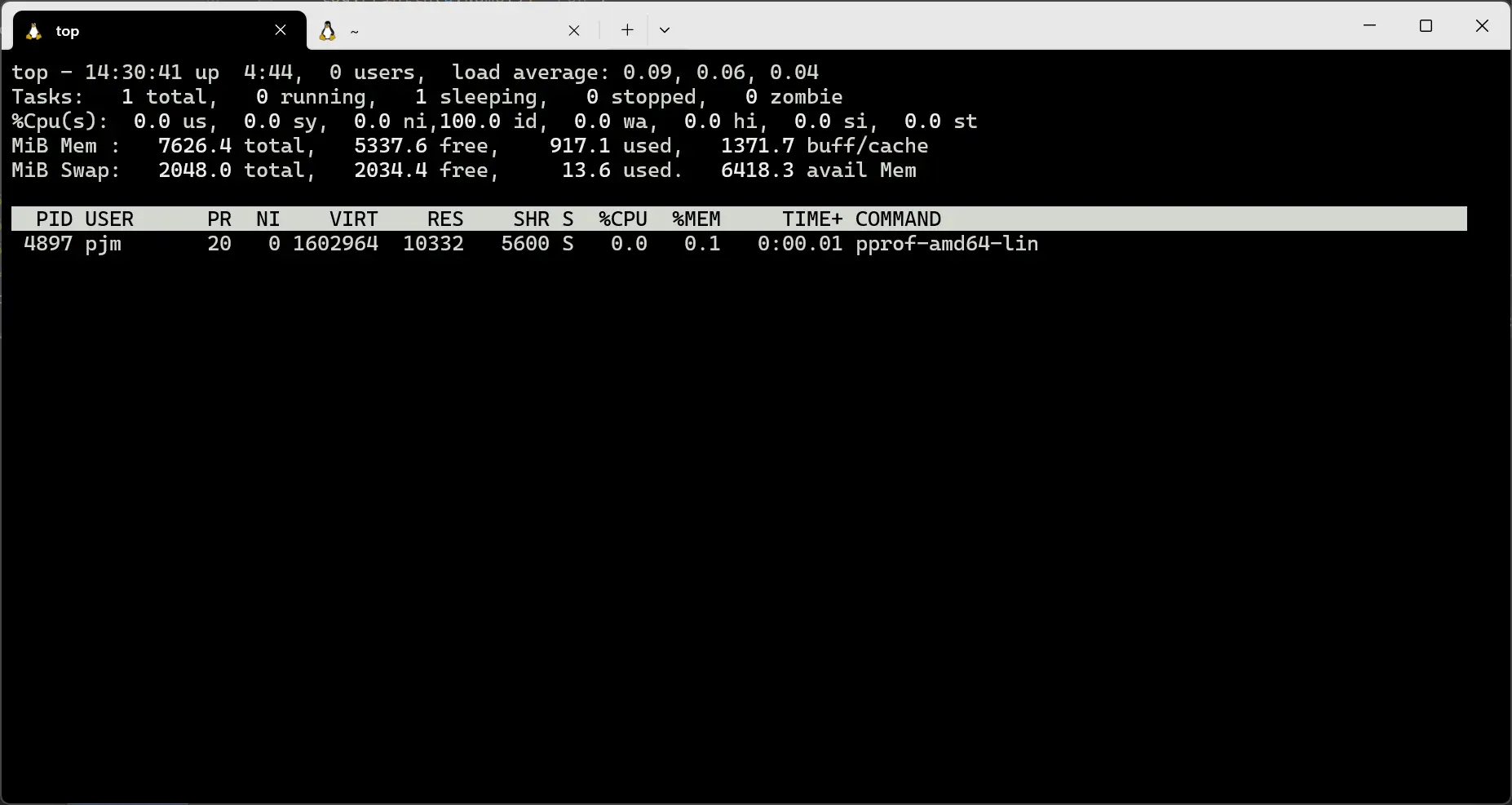
top命令里进程消耗资源情况
过了一段时间之后,我们可以清楚的发现程序内存开始逐渐增长:
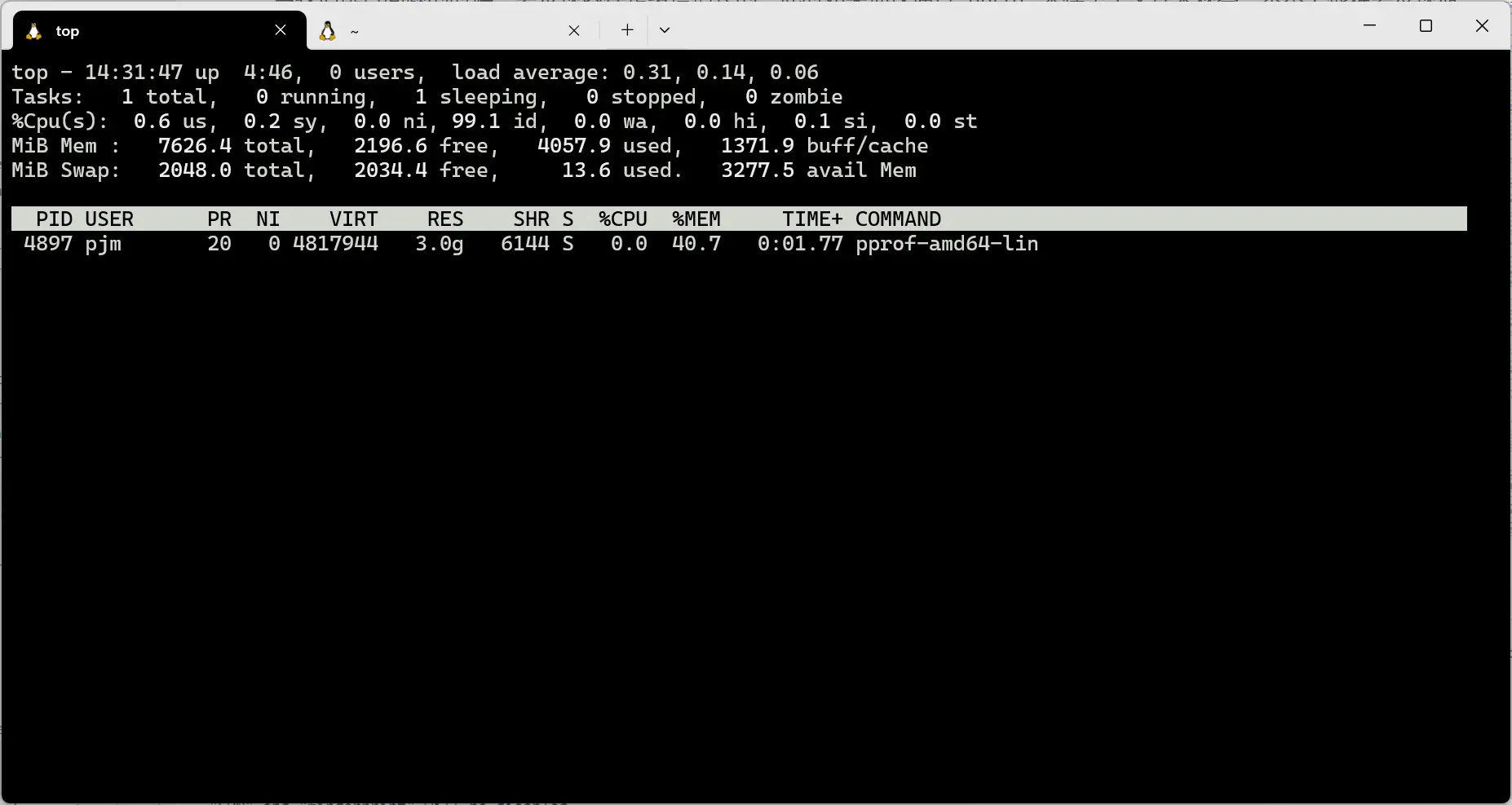
此时我们再执行 curl -o heap-target http://localhost:6060/debug/pprof/heap 获取到当前的采样数据。
再获取到两个样本数据后,我们通过 base 选项将 heap-base 作为基准,查看运行的这段时间内哪里内存增长了
| |
可以发现在这段时间内,Mouse.Pee()方法增长了 768MB 的内存,显然这里发生了内存泄漏。
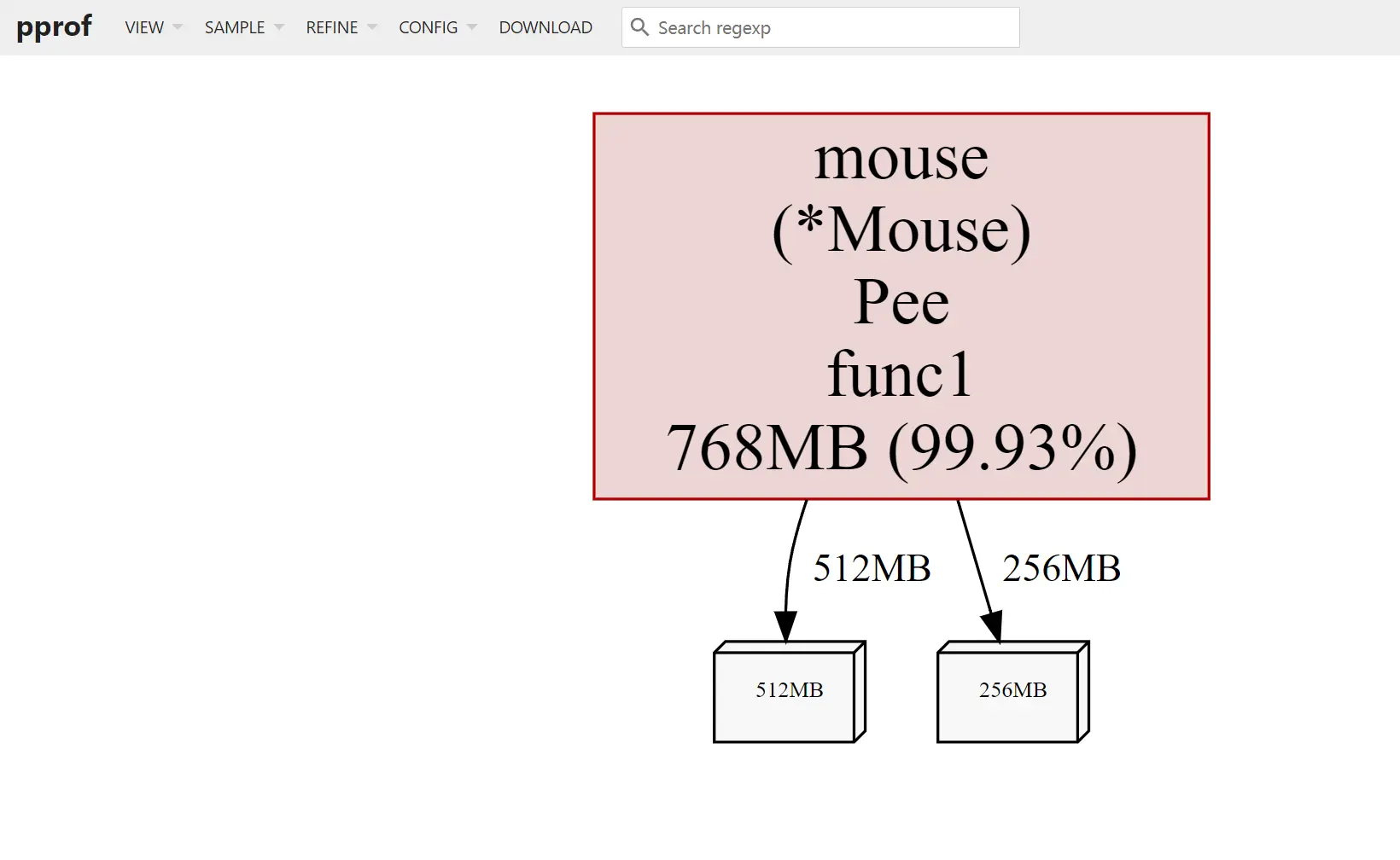
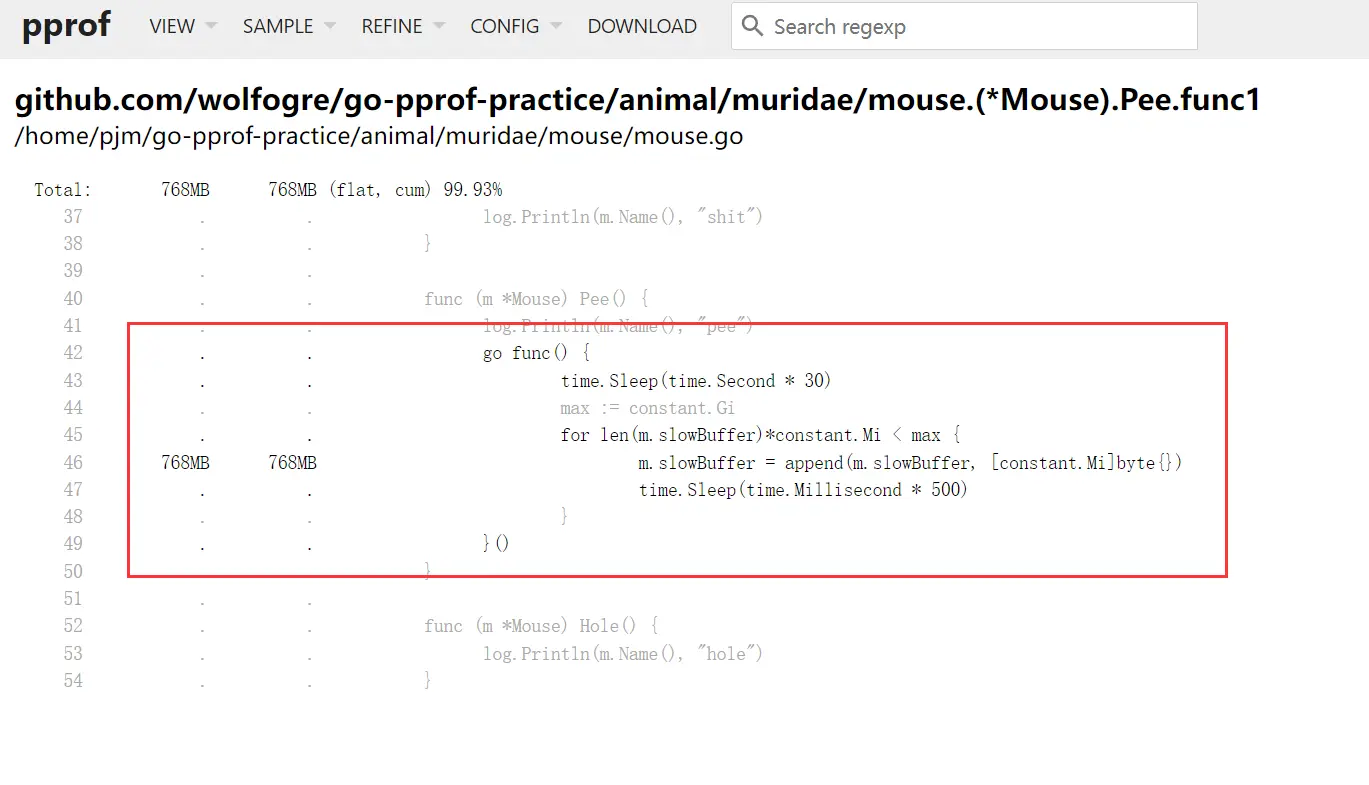
通过查看源码,修复问题。
总结
本文主要内容为 pprof 工具的使用,介绍了通过命令行、可视化等方式进行排查。虽然例子比较简单,但是相信通过这些简单的例子可以让你不在畏惧 pprof。